Despite having thought that I'd said all that I wanted to
say about the Bertrand Paradox, and having provided what I thought was a
definitive case for 1/2 in A Farewell to the Bertrand Paradox as
recent bout of curiosity dragged me back in.
(Someone has asked me what I wanted to prove in Three New Wrong Answers for Bertrand. I didn't intend to prove anything at all, I
was just indulging that curiosity.)
I posted a link to Three New Wrong Answers for Bertrand
and asked a question (at r/math which then got picked up at r/badmathematics) and then the great
piling-on commenced once more. (Note
that I do recognise that a couple of people did say that the question was not
overly bad and I do recognise that my errors and stubborn idiocy associated with goats totally warranted the great piling-on that happened about
three months ago.)
One of the issues that has been raised, a few times, is that
of "random" versus "uniform". Another is "natural" (which in
mathematical terms seems to be interchangeable, at least in part, with
"canonical").
I find this curious, since the phrasing of the Bertrand
Paradox seems to never include the terms "uniform" or
"natural". But I realise that
assumption of "uniformity" and "naturalness" may have some
bearing.
My initial posing of the question was:
Say you have a circle in which
there is an equilateral triangle, like this.

If you pick, at random, a line
which passes through the circle, what is the probability that the section of
your line that lies within the circle will be longer than the sides of the
equilateral triangle?
The Wikipedia wording is:
The Bertrand paradox goes as
follows: Consider an equilateral triangle inscribed in a circle. Suppose a
chord of the circle is chosen at random. What is the probability that the chord
is longer than a side of the triangle?
I deliberately used different and simpler language (in part
to include non-mathematicians and in part to make it a little more difficult to
google an answer within seconds), but I don't think that my wording introduces
or omits anything of consequence.
If I am in error here, then please feel free to enlighten
me.
One phrase which I deliberately didn't change was "at
random" (although I did use the verb "to pick" while Wikipedia
went with "to choose", and in the following I'll even spice things up
occasionally by using "to select").
A question here, that many have asked, and I need to answer, is
"what do I mean by 'at random'".
I could wave vaguely at Wikipedia and their claim that
Bertrand phrased the problem in terms of "at random" and say that I
mean what they mean. I could note that Jaynes also referred to "at random" as supposedly used
by Bertrand and goes on to state that Bertrand himself didn't suggest that any
of the three answers were "correct", because " the problem has
no definite solution because it is ill posed, the phrase 'at random' being
undefined".
So if I did wave vaguely at Wikipedia and Bertrand, then I
could just be saying that "at random" doesn't actually mean anything
specifically. But I would have thought
that in the 125 years or so since Bertrand wrote Calcul des probabilités,
we might have come up with an appropriate definition. Jaynes appears to be suggesting one,
appealing to rotational and scale invariance.
His treatment is a little frightening to someone reading it without a
mathematics degree in their pocket, but I think it aligns with how I think of
it. Again, feel free to let me know if I
have it wrong.
When I think of "at random", I do apparently think
of "uniform". For example, say
that I had 12 balls of two colours:

If I were to repeatedly pick a ball "at random", I
would expect to get a green ball about half the time. If I were to pick one ball "at
random", and one ball only, I would put the probability that the ball
would be green at 1/2. If I repeatedly
picked a ball "at random" and got any other answer, say a third of
the time I get a green ball, I would suspect that my process for selecting
"at random" was flawed - being skewed against the selection of green
balls.
I've put some extra detail on the green balls to try to
explain what I think might be a problem in a selection process. Say I get my colour-blind friend (Ginger) to
select balls at random and write down how many are green, having advised her
(accurately enough) that the blue balls are unmarked. She'll perhaps be a little confused at first,
but will quickly catch on that some balls have G on them and will arrive at the
incorrect conclusion that 1/3 of the balls are green. In this case, I think we'd agree that
something about the process skewed the result against selection of green balls. Or more accurately, against identification of
green balls - sometimes Ginger had a green ball in her hand, but she rejected it,
not because it wasn't green, but because it didn't have G on it (and being
colour-blind, she was relying on this in her identification process).
Then say I get my totally blind friend (Magenta) to help
out, advising her (again accurately) that the blue balls have no braille on
them. She'll come to the conclusion that
1/4 of the balls are green - and again this is because she rejected balls not
because they weren't green, but because they didn't have G on them in braille.
I fully accept that these are bad processes, but that's
partly my point. The processes result in
tossing out of positive hits (green balls) and arrive at a skewed result. In A Farewell to the Bertrand Paradox I
argue that positive hits are tossed out in the 1/3 and 1/4 methods. (Note that from here on in, I'll be referring
to the more traditional methods of selecting chords at random as "the 1/3
method", "the 1/2 method" and "the 1/4 method". I'm also going to be assuming some
familiarity with these methods. Go back
to The Circle, Triangle and Random Line with an Answer if you need to gain that familiarity.)
I further argue that the processes for the 1/3 method and
the 1/4 method can be "corrected".
The 1/3 method involves selecting two points on the
circumference and drawing a chord between them.
The probability can be calculated by imagining the equilateral triangle
rotated until its vertex aligns with one of the points. Then consider the likelihood that the other
point lies in the region that leads to a chord that is longer than √3R (where R is the radius of
the circle and thus √3R is
the length of the sides of the equilateral triangle).

To give you a chord that is longer than √3R, the second point has to
lie below the triangle, along a third of the circumference of the circle. So, it appears that the answer is 1/3.
However, my argument here is that the set of chords selected
by the 1/3 method is skewed. To show how
this skewing can be removed, imagine a slightly different process: draw a line
through the centre of both the circle and the triangle. Then consider a point on that line that is
our first point (Point 1). We could put
it on the circumference of the circle, which certainly seems reasonable, but we
could put it somewhere else that might be even more reasonable - at infinity.
Consider the chords that can be drawn through the circle and
be continued on to pass through Point 1 at infinity. The probability of one of these chords,
selected at random, being longer than √3R
is 1/2. The explanatory figure below is
on its side for convenience.

The problem with using the point on the circumference is
that it skews the set of chords towards those which lie close to the first
point. Here is a graphical
representation of this effect:

In a histogram the effect looks like this:

When you use my method (with y=10R standing in for y=∞), the results look like this:

And, in a histogram, like this:

A close inspection indicates that there are significantly more
very short chords with the 1/3 method than there is with the modification of
that method that arrives at 1/2.
Of course I am aware that 10R is in no sense close to
infinity, but my point here is that the answer rapidly approaches 1/2 as we
move Point 1 away from the circumference of the circle - it's already about 0.49
by the time Point 1 is at 5R. We can
certainly use a significantly more distant Point 1, for example, we get results
like this for Point 1 at 1000000R:


At this point, it's probably best to take a quick look at
the graphical representations of the results for the 1/2 method to see how they
compare:


They seem to be identical.
I have to hold my hand up here though and admit that I have done
something to highlight the similarity.
The standard 1/2 method is to take a radius at random (which is
representative of all radii) and then select a point on this radius at
random. This point is then used as the
midpoint of a chord. My graphical
representations above are done the same way but with a diameter (crossing the entirety
of the circle, rather than just half of it).
Here they are with a radius (at the same granularity):
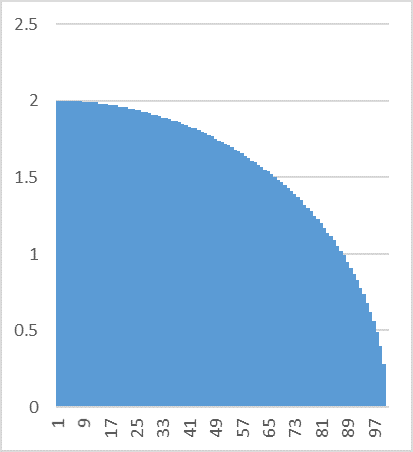
It's only one half of the shape, but this is not
catastrophic because each half is a mirror of the other and each radius can be
continued into a diameter. And in any
event, this shape isn't key. What is
key is the histogram, which looks like this for the radius (at the same
granularity):

If I modify the granularity on the histogram by taking twice
as many samples in the radius, we get:

… which is back to being identical to the
"corrected" 1/3 method histogram.
The 1/4 method involves picking a point at random in the
circle which is then used as the midpoint of a chord. All chords of a length less than 2R are
uniquely defined by their midpoint and all chords of length 2R share the same
midpoint (at the locus of the circle).
One of my interlocutors at r/math, u/DR6,
made a comment about there being problems when "using squares for a
problem that is about circles".
This is precisely the problem (in my humble opinion) with
the 1/4 method, because Cartesian co-ordinates are used within a circle. This is equivalent to chopping up the circle
into arbitrarily small squares and using the centre of each of the squares as
the set from which random points may be selected.
Given that we are talking about a circle, it is far more reasonable
to use polar co-ordinates. This would
mean rather than selecting, at random, values of x and y such that y2+x2<=R2,
we would select, at random, an angle 0
> θ > 2π from the x axis and a distance from the locus of the
circle, r, where 0 > r > R.
Such a scheme automatically makes this method identical to
the 1/2 method, remembering the 1/2 method involves picking a point at random
on a representative radius. The
representative radius represents all possible values of θ.
The benefit of the
polar coordinate scheme is inherent in the notion that the midpoint thus determined
also brings with it an orientation - perpendicular to the radius (so
perpendicular to θ) - including the midpoint with r=0. This does not happen when selecting points at
random using Cartesian coordinates - if (x,y)=(0,0) we have no idea what
orientation the related chord should have, thus unlike all other midpoints, the
locus of the circle defines an infinite number of possible chords of length 2R. For this very reason, we have cause to think
that this method is not "natural".
A similar problem
exists with the 1/3 method, when the second point is collocated with Point 1. There is an infinite number of possible
chords of length 0. Therefore, we have
cause to think that this method is not "natural".
So far as I can
tell, the 1/2 method and the "corrected" variants of the 1/3 and 1/4
methods do not suffer from this problem, and therefore could be put forward as
possibly "natural" methods.
I'm not saying definitively that they are - but I think it is quite reasonable
to say that the others are not.
---
In Three New Wrong Answers for Bertrand I arrived at 1/2 for a method involving
selecting two points (using Cartesian coordinates) inside a boxed circle. However, even after a million iterations,
it's not still actually quite 1/2 - it's 0.52-ish. This is close to 1/2, but's not close enough
to count as 1/2 as far as I am concerned - and in any event, the histogram
looks wrong. While I might be being hasty,
I suspect that something is wrong this method even if it arrives at an answer
that is tantalisingly near to 1/2.
Dear wotpolitan,
ReplyDeleteI'm glad to see that you are still trying to solve mathematical problems, but I am a little bit disappointed to see that you are still not using words as they should be used and that you still fall into common misconception about probabilities.
Your whole point seems to be that the answer 1/2 is THE answer to Bertrand's paradox, and that other methods of choosing a chord are skewed. I'm not sure that I could explain why this is not a valid point directly, so I'm really going to use your own words to make you see where your errors are.
First, the wording of the problem. Apparently, you seem to think that the sentence :
> If you pick, at random, a line which passes through the circle
is equivalent to the initial formulation :
> If you pick, at random, a chord of the circle
You even say :"I deliberately used different and simpler language, but I don't think that my wording introduces or omits anything of consequence." and this is a major flaw in your reasoning. It has many consequences. I would go even further, the Bertrand "paradox" (which is no paradox at all, but that's another question) is ultimately an example to understand that some sets do not come with a natural parametrization. If you change the wording of the problem by identifying the given set with another new set, then is is entirely possible that the new set has a natural parametrization.
What you are doing with your rephrasing of the problem is that you inadvertently choose a particular parametrization of the set of chords. You are actually identifying the set of chords with the set of lines which passes through the circle. Now, this parametrization is useful and natural, but it is in no way unique. There are many other way to identify the set of chords to some other set. For example, I can identify the set of chords and the set of pairs of point on the circle. I can also identify the set of chords and the set of points inside the circle. Both identifications are perfectly natural and very useful.
Imagine that I ask you the problem in the following way :
> If you pick, at random, two points on the circle, what is the probability that segment between these two points will be longer than the sides of the equilateral triangle?
I deliberately used different and simpler language, but I don't think that my wording introduces or omits anything of consequence. (Does this sentence remind you of something ?) Is this wording of the problem less or more natural than your own wording ? I argue that both are natural, but both are not equivalent to the original wording ...
It might seem obvious to YOU that your wording is more natural. It might seem more obvious to ME that my wording is more natural. But in the end, there is absolutely no reason to think that one is better than the other.
It seems that I need to cut my comment in two half because it is too long ... so I will get back after a short break
Now after this wording of the problem, you argue that the answer should be 1/2, referring to Jaynes treatment. I agree with you, but I don't think that you understand the words you are using :
Delete> Jaynes appears to be suggesting one, appealing to rotational and scale invariance.
Let me ask you a question. I give you a precise circle. The set of chord of this precise circle is a well-defined set. Why does it mean for a measure on this set to be "scale invariant" ?
The "scale and rotational invariance" is meant to be applied to a measure on the set of all lines in the plane. This is a completely different set from the set of chord on a specific circle. Now, what Jaynes meant is that if we choose a parametrization of chords as lines that passes through the circle, then we should put a measure on the set of chords that comes from a measure on the set of lines. Moreover, the measure chosen on the set of lines should not depend on the placement of the circle (translationally/rotationally invariant) and on the size of the circle (scale invariant). And fortunately, there is a unique measure on the set of all lines in the plane that satisfies these properties.
But I can choose a different parametrization of the set of chords, for example by the two endpoints on the circle. Then there is absolutely no reason to think that the measure on the set of chords should come from a measure on the set of lines. And the expression "scale invariant" is meaningless here, because the circle is fixed, and the circle is NOT scale invariant. The only thing that would make sense is "rotationally invariant". It turns out that there is a natural measure on the set of pairs of points on the circle, and it gives you a DIFFERENT measure on the set of chord.
> However, my argument here is that the set of chords selected by the 1/3 method is skewed.
Skewness is a relative notion. In this problem, there is no point of reference which would be the "unskewed" result.
The fact that you can get back the 1/2 answer by pulling one of the endpoint of the chord towards infinity is rather neat. But it is in no way an indication that 1/2 is a better result ...
> This is precisely the problem (in my humble opinion) with the 1/4 method, because Cartesian co-ordinates are used within a circle.
What ??? Again your misunderstanding of basic mathematics is surfacing. There is absolutely no reason to use cartesian coordinate to define a uniform probability distribution on the disc. And moreover, you can use cartesian coordinate without "skewing" the result.
But more importantly your method of "randomly choosing a point in che circle" :
> we would select, at random, an angle 0 > θ > 2π from the x axis and a distance from the locus of the circle, r, where 0 > r > R
does not produce the result that you probably think it produces. The probability measure that is induced by this process is not the uniform probability measure on the disc ...
If you were familiar with polar coordinates, you would know that the usual area is given by "r dr dθ", but what you did was taking the measure given by "dr dθ" (I'm simplifying the argument because it seems irrelevant to make a full course on measure theory here). Of course, your mistake is "lucky" because it produced the result that you wanted : 1/2. But the mistake is real, and hence the result is relatively meaningless.
In conclusion, your main mistake is to think that there is only one natural parametrization of the set of chords. But even if there were a "best" parametrization, it is irrelevant in the context. You should understand that the Bertrand paradox is not about chords at all ...
Perhaps I should give you another example of a similar problem :
* Pick, at random, a right triangle inscribed inside a circle of diameter 1. What is the probability that one angle of the triangle is less than pi/6 ?
How would you answer the question ?
I've responded here.
Delete